

Mythos-class AI and the end of the patch window
The discussion around Mythos-class AI models can sound abstract very quickly: frontier capability, export controls, zero-days, benchmark scores, restricted access, leaked weights. Those details matter, but they are not the part that should keep security teams awake.
The important change is more practical. AI is starting to remove the human bottlenecks from vulnerability research. A capable model can read unfamiliar code, form a hypothesis, run tests, debug the failure, adjust the approach, and keep iterating. Work that used to depend on scarce expert time can now be parallelized by agents that do not get tired, do not wait for office hours, and do not need the same depth of experience to make progress.
That changes the exploitation landscape.
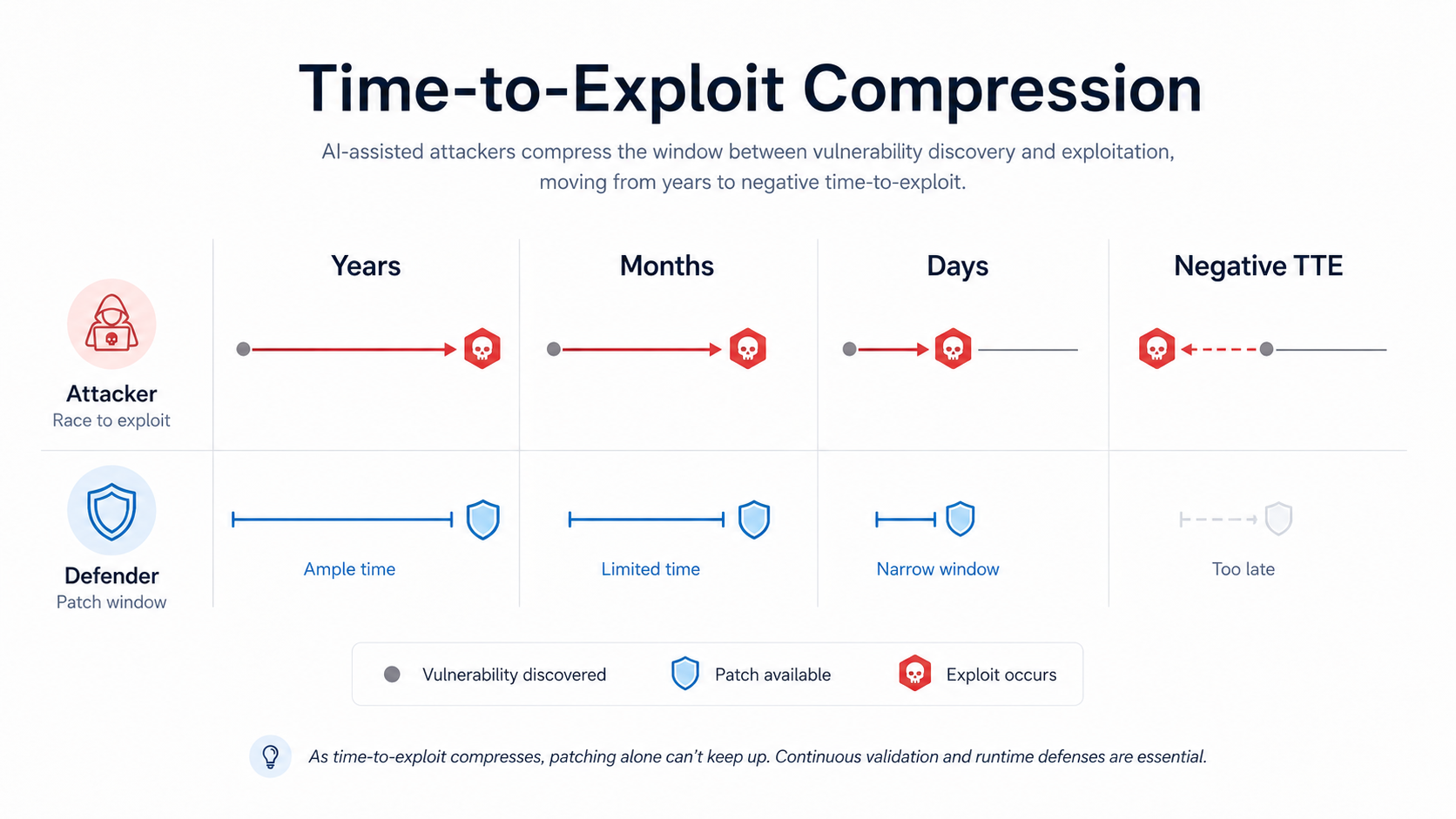
A vulnerability disclosure used to create a window. Security teams could assess exposure, prioritize, find an owner, schedule a maintenance window, patch, and then verify. It was never easy, but the process assumed that defenders had time to move through the queue.
Mythos-class models attack that assumption. As similar capability becomes more available, the time between "this might be a weakness" and "this is a working exploit path" keeps shrinking. In some cases, exploitation will begin before defenders have a clean patching path at all. That is what people mean when they talk about negative time-to-exploit.
Patching still matters. Vulnerability management still matters. But neither can be the only defensive bet when the attacker's agents are moving faster than the enterprise change process.
Mythos is a signal, not the whole story
Mythos should not be treated as a single magic hacking tool. It is a signal of where the economics are going.
Traditional vulnerability operations are built around known information: known CVEs, known versions, known exploitability signals, known prioritization models. That operating model is still useful, but it is incomplete when models can help discover and weaponize previously unknown weaknesses at machine speed.
The exact model name is less important than the direction of travel. Mythos, GPT-5.5-class systems, future open models, private frontier systems, and offensive agents built on top of them all point toward the same problem: attackers will have more automation inside the research and exploitation loop. Some teams will use that capability defensively. Some adversaries will use it offensively. The technology does not care which side is using it.
For defenders, the question changes from "can we patch faster?" to "can we keep the enterprise safe while patching is still in progress?"
That is the same operating shift we wrote about in our CERT-In AI Blueprint analysis. Security has to become continuous, threat-informed, and evidence-led. Mythos-class capability makes the reason much sharper: if attackers can produce and adapt exploitation paths faster, defenders need systems that validate and improve defenses faster too.
The attacker advantage is iteration
Most security programs are not slow because people are careless. They are slow because production environments are complicated.
A typical vulnerability workflow has many sensible steps. A scanner finds an affected asset. Someone checks whether it is internet-facing, whether it supports a critical business process, whether a compensating control exists, whether a patch is safe, who owns the change, and when it can be deployed. That caution exists for a reason. A bad patch can break payment systems, customer portals, core banking processes, and audit-critical workflows.
The problem is that attackers do not inherit that process. AI-assisted attackers can run a different loop:
- inspect software or exposed behavior,
- generate a hypothesis,
- test it,
- debug the failure,
- mutate the approach,
- repeat until something works.
That loop is not perfectly autonomous today, and it will not produce a critical exploit every time. But it is getting cheaper, faster, and easier to scale. That is enough to change defender timelines.
The uncomfortable part is that defenders often optimize for queue management while attackers optimize for iteration speed. A ticket can be correctly prioritized and still be too late. A patch can be approved and still arrive after exploitation. A control can exist and still fail to fire when the behavior appears in the environment.
That is why Mythos-class risk cannot be handled only as a vulnerability management problem. It becomes a security operations problem.
Detection readiness becomes the safety layer
When the patch window collapses, the enterprise needs a second line of evidence: whether it can detect and respond to exploitation-like behavior while remediation is still underway.
This is detection readiness. It is not a vague maturity term. It is the ability to answer practical questions with data:
- If an exploit succeeds on an internet-facing system, does endpoint or workload telemetry show the follow-on execution?
- If the attacker tries to escalate privileges, access credentials, or move laterally, which detection fires first?
- If command-and-control traffic appears, does the web or network stack create a useful signal?
- If data is staged or exfiltration is attempted, do DLP and monitoring controls see it?
- If the SOC receives an alert, does it have enough context to triage quickly?
- If engineering tunes a rule or changes a policy, can the team re-run the same behavior and prove the outcome improved?
AI may accelerate exploit discovery, but exploitation still produces behavior. Attackers still need execution, persistence, credential access, lateral movement, defense evasion, command-and-control, data staging, and exfiltration. Those behaviors are observable if the telemetry exists, the detections are mapped, and the SOC has practiced the response.
The hard part is not writing a slide that says those controls exist. The hard part is proving they work this week, in this environment, against the behaviors that matter.
If your team needs to answer those questions with data instead of assumptions, book a demo FourCore ATTACK validates detection readiness against real adversary behaviors in your own environment, so you know exactly which controls hold and which ones need attention.
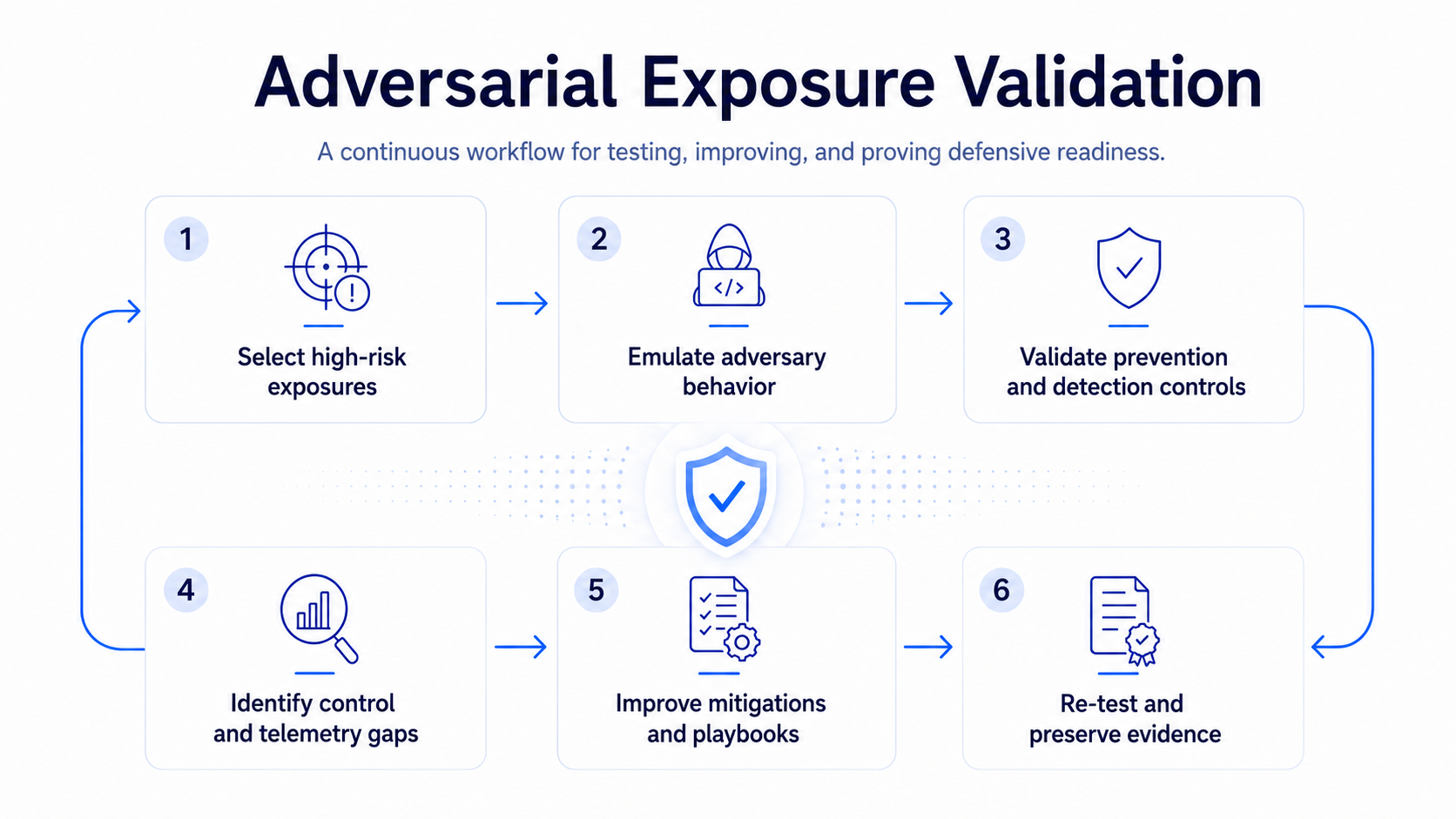
What FourCore ATTACK is built to validate
FourCore ATTACK is built around adversarial exposure validation. The job is to safely emulate adversary behavior and measure whether the controls already deployed in the enterprise detect, prevent, and support response under realistic conditions.
That makes it useful in a Mythos-class world because the platform is not trying to predict every future CVE. No one can honestly promise that. Instead, it tests the defensive layer that has to hold when exploitation arrives before the patch cycle is complete.
The platform helps teams validate questions such as:
| Capability area | What teams can validate |
|---|---|
| Endpoint control validation | Whether endpoint security detects or prevents execution, persistence, privilege escalation, defense evasion, credential access, and other MITRE ATT&CK-mapped behaviors. |
| Email security validation | Whether email controls stop payload delivery, phishing patterns, attachment-based threats, and user-targeted intrusion paths before they become initial access. |
| Web gateway and network validation | Whether outbound communication, command-and-control patterns, and suspicious web activity are visible and controlled. |
| WAF and application-layer validation | Whether exploit-like application behavior creates the expected prevention, logging, and SOC visibility without requiring a real vulnerable application or a destructive attack. |
| DLP and exfiltration validation | Whether attempted data movement over channels such as HTTP, HTTPS, and TCP is detected for sensitive data patterns relevant to the enterprise. |
| SIEM and SOC validation | Whether telemetry is ingested, parsed, correlated, triaged, and turned into useful investigation evidence. |
| Remediation evidence | Whether teams can see what worked, what failed, what was tuned, and whether re-testing confirmed improvement. |
The point is not to replace patching, scanners, EDR, SIEM, WAF, DLP, or human red teams. The point is to make those investments measurable. If a control is deployed but does not detect the behavior, the enterprise needs to know that before an attacker finds out for them.
What BFSI teams should do differently
For BFSI organizations in India, this is not only a technical problem. It is an operating model problem.
Banks, insurers, payment companies, and financial services firms already deal with strict expectations around resilience, incident response, third-party risk, auditability, and control effectiveness. Mythos-class exploitation compresses the time available to show that those controls are working.
A practical readiness workflow looks like this:
- Identify the systems where exploitation would matter most: internet-facing applications, identity infrastructure, critical endpoints, payment workflows, crown-jewel data stores, third-party access points, and business units with high operational risk.
- Map the post-exploitation behaviors that matter for those systems. Do not stop at the CVE. Look at execution, privilege escalation, credential access, lateral movement, persistence, command-and-control, data staging, and exfiltration.
- Run safe adversarial validation against the controls in place. The goal is to test the behavior, not to wait for a real breach or a long red-team window.
- Review the SOC outcome. Did the alert fire? Did the log arrive? Did enrichment work? Did the analyst have enough context? Did the playbook match what happened?
- Fix the actual gap. Sometimes the issue is a missing log source. Sometimes it is weak correlation logic, an EDR policy, a WAF exception, a noisy rule, unclear ownership, or a playbook nobody has practiced.
- Re-test and preserve evidence. Improvement only counts when the same behavior produces a better outcome the next time it is run.
This is the loop defenders need now: validate, improve, re-validate. It is slower than a slogan and faster than waiting for the next annual assessment.
The metric that should change
If Mythos-class models compress exploitation timelines, defenders need to compress their own improvement timelines.
A useful question for leadership is not simply "how many vulnerabilities are open?" That number matters, but it does not show whether the enterprise can survive exploitation while remediation is underway.
The better questions are more operational:
- How long does it take us to validate controls against a newly relevant attacker behavior?
- Which techniques are prevented, which are only detected, and which are missed?
- Which business units have inconsistent telemetry or detection coverage?
- How quickly can we move from a failed validation to a tuned control?
- When we tune the control, how quickly can we prove the fix worked?
This gives security leaders a more useful way to talk about risk. It connects vulnerability management, SOC operations, detection engineering, and leadership reporting into one measurable loop.
From validation to mitigation
Validation only matters if it leads to better defenses.
This is where many programs get stuck. They find the gap, write the report, and then the work slows down. The owner is unclear. The fix is spread across policy, logging, detection logic, endpoint configuration, WAF rules, or user awareness. By the time the change lands, nobody re-runs the same behavior to confirm that the gap actually closed.
FourCore ATTACK is designed to keep that loop visible. A failed or partially successful validation should lead to concrete mitigation work: restrict a behavior, add or tune a detection, adjust a control, improve a playbook, assign ownership, and then test again. We think of this as a mitigation control center for improving defenses: a practical way for teams to carry the context from validation into remediation, track the work with the right owners, and return to the evidence when they need to prove that the defense improved.
Build faster than the attacker's agents
The lesson from Mythos-class models is not that defenders should panic or pretend every organization can patch every weakness before exploitation. That is not how real enterprises work. The lesson is that security programs need a faster defensive feedback loop. If attackers are using agents to discover, test, and adapt exploitation paths, defenders need systems that continuously test whether controls hold, show where they fail, drive mitigation work, and prove improvement after changes are made.
That is the practical shift. The organizations that do well in this environment will not be the ones with the longest list of tools or the loudest AI claims. They will be the ones that can move from assumption to evidence quickly, and from evidence to improved defenses before the attacker's agents get there first.
If you want to see how that feedback loop works in practice, book a demo. FourCore ATTACK helps teams test relevant attacker behavior, turn a miss into owned remediation work, and rerun the same test once the change is in place.
